TL;DR — I joined Stuart in 2015 as a CTO, and the first big decision I had to take was moving away from the legacy codebase. How do you do that live, while growing business? This is some of the ideas we had allowing us to successfully transition from a PHP codebase to our new Ruby Stack. This post follows a talk I did at Kikk (video available) and 50Partners.
This is not a comparaison between PHP and Ruby, and I see nothing wrong in using any of those. We’re actually looking at adding other languages to our stack like Elixir, Go or more Node.js as they all have very good use cases.
Stuart is always hiring coders and you should talk to me if you’d like to be part of it. We offer competitive salaries, a good environment and allow remotes.
I am also available if you need a speaker at a conference.
Summary
The quick list which I think helped me to move legacy code to new code, in a new environment with an existing team:
- Try to detect who can help you in the existing team, and who is burned or not willing to help at all. You’ll need everyone at their best to achieve such a massive change.
- Select a way to make the old legacy code and the new code interact. At first you’ll need to be able to insert method calls from legacy code to the new code, but you might very quickly need to insert method calls from the new code to the old code as well. Sidekiq works but you may go to Kafka, RabbitMQ or Amazon SQS. You could think a quick HTTP API would work but I think it’s way too much hassle.
- For API calls, implement a dynamic routing system to be able to redirect some endpoints to the new code stack.
What you do when you join an existing project
The first weeks I talked with the existing team, and tried to feel how the code was built. I sadly discovered close to no test coverage, and a bigger codebase than expected (about 90k LOC PHP). The SQL schema was way over engineered, and too many tables were used as configuration settings instead of data store.
This is an issue I had with many previous projects I’ve helped building while I was doing software consultancy.
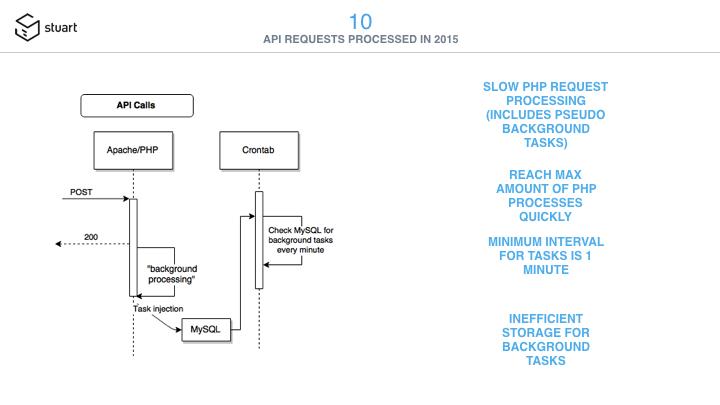
Slide #10 shows a few issue I had with existing code, reaching the max amount of PHP processes quickly and using crontab for background jobs. I decided to move forward a stack I already had implemented using Ruby with components like Rails, Sidekiq, and Grape.
Moving on
Rewriting software is a necessary and normal process for the life of any project. Refactoring is something you should do monthly, if not weekly, but sometimes it’s not enough and you should then rewrite complete part of your system.
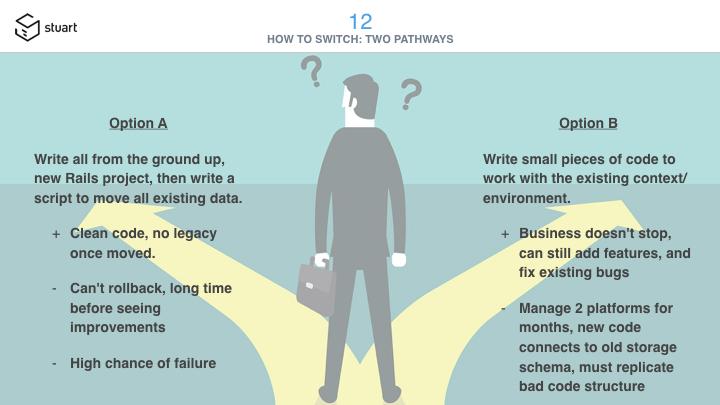
When rewriting a complex project you have basically 2 options:
-
Options A: Rewriting using the new stack from the ground up and write a script to move all existing data, knowing you won’t be able to rollback because you didn’t plan to be able to run that script the opposite way. It’s highly risky, stops all new feature on the project since everyone wants to work on the new stack, and you’re going in a tunnel for months without any view on when it will be over.
-
Option B: Writing the new code connecting to the existing DB (schema and data), trying to slowly replace existing modules and delegate those to the new code. You can optionally start writing new features earlier, and write the new code in a way it helps fixing bugs in the existing legacy codebase.
I chose option B, and I’m glad I did.
Start the new codebase
I fired up a new Rails project, automatically generated Active Record classes
based on the existing tables1, using tricks like self.table_name= to keep
the same table names, and connecting models with belongs_to. I also used
Active Admin to have a quick view on the existing
data without using a SQL client. From the beginning I used
Vagrant to make sure it was easy for everyone to
contribute to that new project as well
(Docker wasn’t great for macOS).
After my first 3 days I had a good start and I knew I was going in the right direction.
Connecting both codebase
I decided to massively use Sidekiq for background tasks, as it stores them in Redis with a very simple format and existing PHP libraries allows to inject jobs from PHP to Ruby. It’s a good way to easily move away from the legacy code we had.
Using feature flag with Rollout and its PHP clone allowed to clone existing behavior into Ruby, and then use Redis to turn on/off that code execution from PHP to Ruby, and rollback if the new code wasn’t doing what it was supposed to. The same flag would enable code execution on Ruby, and disable it in PHP.
Moving on basically meant asking a PHP engineer to move a feature into a single function call, then implementing the same on the Ruby side and use Rollout to turn the Ruby code on.
The first part of the PHP code we’ve moved to Ruby was outgoing emails, it was easy to check it was working and allowed us to quickly leverage Rails features and send nice HTML layout emails. We then moved all our mobile Push Notifications which have a similar pattern (PHP doesn’t need anything back once it decides to send a push notification or an email).
Fix bugs in the existing codebase
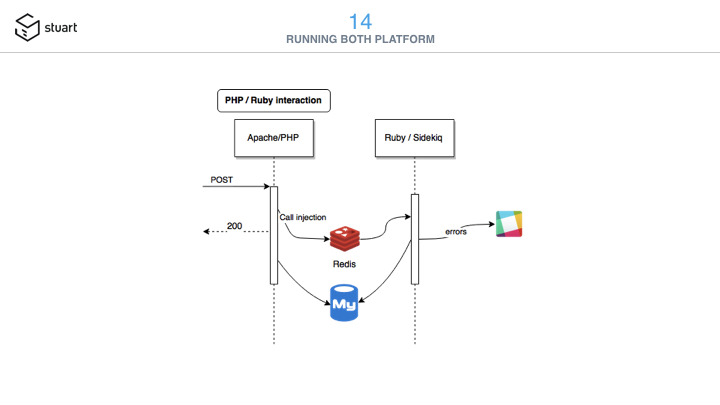
We had issues with the legacy codebase, like database inconsistencies. I asked
the PHP engineers to leverage Doctrine and insert two method calls into Sidekiq
for every DB creations or updates. Sidekiq then received zillion of calls per
day, allowing me to be aware of DB changes inside an ActiveJob. I then
added ActiveRecord validation methods with a code looking like:
And sent validation errors to a Slack channel dedicated to the PHP team. It helped them a lot about existing bugs and making sure those weren’t repeated.
API calls
Once we had all background jobs worked on, the 2nd biggest part was the API calls. We looked at Kong if it allowed dynamic mapping based on URL but it wasn’t available at the time. We used NGINX and its proxy feature with a map file to tell NGINX to proxy to our PHP or Ruby instances based on the URL called.
This way we could say all /v1/jobs/:id should be sent to our Ruby instances,
while sending other endpoints to our PHP instances. Same as when moving the
background tasks codebase, we first moved an easy non-critical endpoint (job
ratings) to validate the system and once we were confident about it, we started
to move the most critical ones. We noticed an instant improvement over our API
calls compared to our previous stack.
One of our PHP engineer managed the move by listing all endpoints in a wiki page, and adding red/green flags for all environments (slide #22) like staging, sandbox, production. Our QA team then made sure the input/output for the API endpoints calls were the same as before, to avoid our partners and integrator to have to do any updates on their integration.
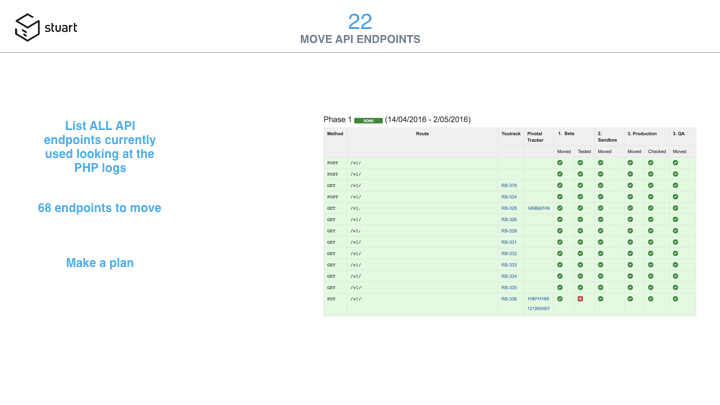
We moved 68 endpoints over a few months.
Remove boilerplate code
A lot of the existing tables were actually used as Settings tables, we moved
all those into standard regular Ruby classes, in a way you can interact with
them the same way as ActiveRecord classes, but including the data inside the
code. We moved all tables with less than 10 rows to static code instead.
Conclusion
We changed 90k LOC to about 15k LOC, while adding features and improving existing ones. Our test coverage went to about 70% and CodeClimate quality is now about 3.95.
We also increased our business metrics and improved the system reliability.
I expected the code to be moved within about 3-4 months, but it took 8 months before we removed existing PHP servers from production. We noticed major improvements after about 2 months and then quality kept improvement rapidly. Both platform ran so smoothly it took much longer to completely disconnect some non-critical PHP code. The reason being nobody wanted to take care of those as they were working fine.
If I had to redo this, I would ask our devop team to implement ephemeral
servers, those are time saver for the engineering team. Any engineer pushing
code to a GitHub PR calls a
Jenkins, runs the test and if they succeed creates a
Docker image and push it to a Kubernetes cluster, loads a
smaller version of our production database and makes it available to a specific
DNS like your-branch.stuart.dev with mandatory VPN access.
I often get asked what happened with the previous team, most of them left early or got let go when we decided to move away from the legacy codebase. A few decided to stay to help us moving away, and a year later almost all left to new projects.
People is the most important part of your company, you should treat them respectfully but also understand than people leaving is part of most company these days and I consider normal someone leaving when they want to pursue other projects.
Thanks
I’d like to publicly thank the team members who made that move possible, Albert, Alejandro, Alvaro, Lachy, Loic, Mathieu, Romain.
Many joined since and you can see the whole team at stuart.com. We also hire at all time, give me a shout if you’re interested.
I hope you found this post useful. If you did, drop me a note at @fabienpenso. If you didn’t, drop me a note anyway telling me how to improve it.
You can stay up to date via my RSS feed. Thanks for reading.
-
I basically looped through all existing tables, looking at their name and generating empty
ActiveRecordclasses with somebelongs_tobased on table attributes. I also generated a genericActiveAdminfile to list all existing models. ↩